728x90
반응형
python으로 epub 목차 가져오기
처음에는 toc.ncx 을 읽어 하나 하나 파싱하려고 했는데
좋은 라이브러리가 있었다.
book 객체에 epub 정보 담아두고
book.toc 불러오면 바로 읽히더라 굿
import ebooklib
from ebooklib import epub
from bs4 import BeautifulSoup
# EPUB 파일의 목차를 리스트로 저장하는 함수 (book.toc 사용)
def get_toc(epub_file):
book = epub.read_epub(epub_file)
# book.toc을 통해 목차 정보 가져오기
toc_list = []
def parse_toc(toc_items):
for item in toc_items:
if isinstance(item, tuple):
toc_list.append((item[0].title, item[0].href)) # 제목과 파일 경로 저장
if item[1]: # 하위 항목이 있는 경우 재귀적으로 처리
parse_toc(item[1])
else:
toc_list.append((item.title, item.href))
parse_toc(book.toc)
return toc_list, book
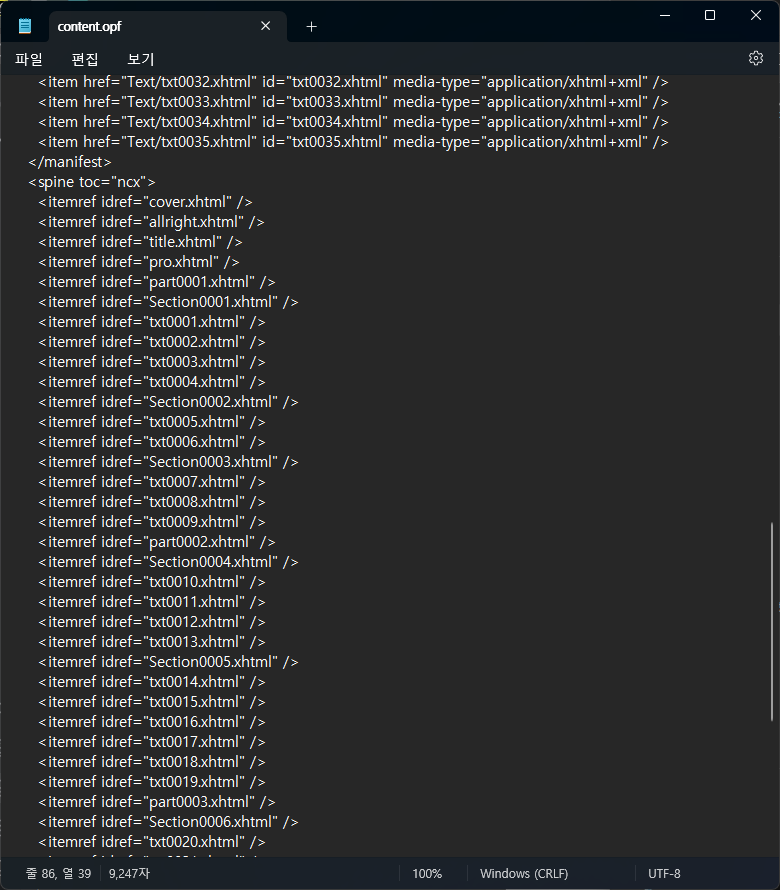
html 파일 순서 알아내는 방법
이건 content.opf 파일에 들어있는데, spine 항목을 보면 된다.
마찬가지로 book.spine을 이용하면 됨.
728x90
반응형
'사이드 프로젝트 > [TeleReaderBot] 텔레그램으로 전자책 읽기 📙' 카테고리의 다른 글
| 텔레그램으로 전자책 읽어주는 봇 (1) | 2024.10.22 |
|---|---|
| 텔레그램 봇 생성과 토큰 얻는 방법 + 챗 아이디 얻기 (0) | 2024.10.22 |
| 카카오톡 API vs 텔레그램 Bot 선택 과정 (0) | 2024.10.22 |






